
对于垂直搜索引擎来说,网络蜘蛛是非常重要的,因为在垂直搜索领域,数据的收集工作都是由蜘蛛程序来完成的。 垂直搜索引擎除了要设计蜘蛛程序外,还要管理这些蜘蛛程序的运行,这是比较复杂的工作。如果缺乏一套有效的管 手段,那么垂直搜索引擎将面临一场恶梦。还有一点非常重要的是,现今的网站当中,有越来越多的动态内容,能不能 抓取这部分内容,将会体现出网络蜘蛛功能的高下。
幸运的是,我们有了海蛛--这个垂直搜索专用网络蜘蛛系统。有了海蛛,垂直搜索更简单! 使用了海蛛,一切变得有条不紊,变得简单起来。
海蛛七大功能特色
一、提供WEB管理接口,操作方便
海蛛启动后,用户可用浏览器访问http://localhost:6070(注:6070为默认端口,用户也可修改此端口号),登录后 便可进行查看系统信息、管理任务和修改登录用户名及密码的工作。任务管理包括新建、修改、复制、启动、停止等 项。一切都是通过浏览器来进行,非常简单。
二、如何持久化数据,用户决定
对于抓取到的数据,如何持久化的问题是由用户决定的,海蛛提供了持久化的接口IDataPersist,用户端需要实现这个 接口。关于用户是如何实现的,海蛛并不关心。通过采用接口方式,用户持久化数据有了非常大的灵活性,对于不同 类的数据,能够采用不同的方式进行持久化,满足了实际需求。亦即,抓取来的数据既可存到文件中,也可数据库中, 更可通过网络传到另外一台机器中。这一切都由用户根据实际情况来决定。
三、采用javascript编写蜘蛛程序,修改容易
蜘蛛程序既可用C/C++等编译型语言来编写,也可用javascript、ruby、python等动态型脚本语言来编写。编译型语 言不能直接执行,需要经编译器译成机器码后才能执行,速度较快,但维护不方便。动态脚本语言能马上执行,没 有编译这个过程,编写容易,修改容易,维护也容易。有鉴于蜘蛛程序运行于后台且维护量比较大,我们采用了脚 本语言javascript作为蜘蛛程序的编写语言。
海蛛为蜘蛛程序提供了内置的document对象,通过这个对象,蜘蛛程序可以访问到当前抓取到的文档的任何位置的数 据,并可将数据进行持久化。下面一段代码能将网页的纯文本内容抓下来:
var map = new java.util.HashMap();
map.put('body',document.string('/html/body'));
document.saveData(map);
其中,document.string用于获取指定节点的文本内容,而document.saveData则用于将数据持久化。怎么样?简单吧。
四、蜘蛛程序运行时间多样,选择灵活
为了适应各种情况,海蛛提供了多种运行时间选择:手动运行,每隔X分钟,每隔X小时,每天X时X分,每周周XX时X 分,每月X日X点X分,每年X月X日X时X分。这些时间选择,完全满足了数据抓取任务的要求。
每项任务都可选择自己的运行时间,任务启动后,海蛛会在合适的时刻运行此项任务,执行数据的抓取工作,经由用 户提供的持久化类,将数据保存起来。
五、采用海葵抓取网页,信息完整
为了获取结构化的网页数据,并且得到网页的完整数据(静态或动态的),海蛛采用了海葵--这个全球首款基于浏 览器构建的垂直搜索专用网页抓取服务器来作为后台的抓取工具。自1.1.0版开始,海蛛不再区分海葵的抓取模式了, 而是采用了全新的种子结构,即URL+节点的XPATH,统一操作,方便垂直搜索引擎开发人员。海蛛运行中,会自动 分析页面,产生种子,蜘蛛程序开发者只需考虑如何分析数据即可。这些种子中,不仅包括正常的链接(即<a href="URL">), 也包括调用javascript实现页面切换功能的两类链接,一种类似<a href="javascript:..." >,另一种类似<a href="#" onclick="...">。 凭借海葵的强大功能(EXEC、CONTINUE、NODATA、getNodeByXPath),所有链接的网页数据不管有没有动态内 容,都可轻松得到。
六、支持多种数据库
海蛛支持通用的数据库PostgreSQL,MySQL,Oracle,SQL Server,支持嵌入式数据库HSQLDB。HSQLDB已内置到海蛛中, 勿需另外安装,方便用户测试和执行轻量级的抓取任务。如果抓取任务多,并发运行的线程多,就需要采用PostgreSQL,MySQL,Oracle,SQL Server数据库。注意,数据库均需采用utf8编码,这样才能保证输入汉字不会出现乱码现象。
七、支持多种操作系统
不仅支持Windows操作系统,还支持Linux操作系统。用户可下载适合自己的版本。
想做一个垂直搜索引擎吗?使用海蛛吧,它让您如虎添翼!
想让您的垂直搜索引擎工作得更好吗?使用海蛛吧,它让您省力省心!
海蛛,让垂直搜索更简单!
seaspider-4.4-installer.exe
(适用于Windows系统)
seaspider-4.4-fc9.tar.gz
(适用于Fedora Core 9兼容的Linux系统)
seaspider-4.4-el5.tar.gz
(适用于RedHat EL 5/CentOS兼容的Linux系统)
*安装海蛛*
WINDOWS: 双击海蛛安装程序,最后启动海蛛服务。
LINUX: 解压海蛛安装包,执行bin/seaspider start,启动海蛛服务。
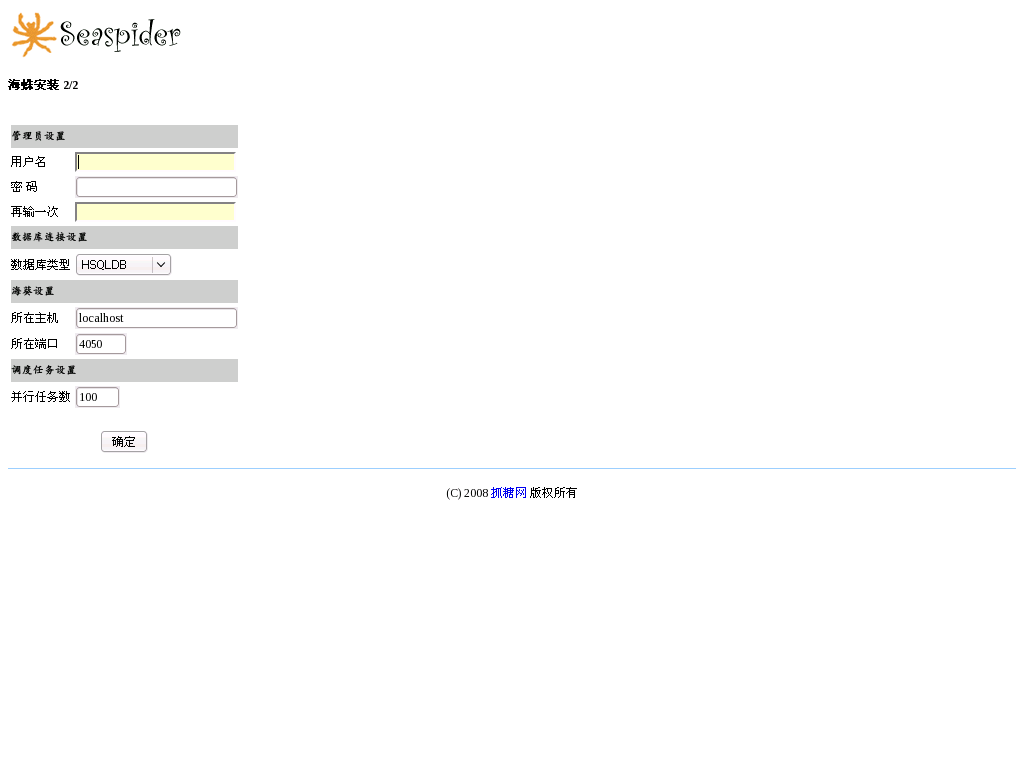
海蛛启动后,通过浏览器访问海蛛所在端口(如http://localhost:6070)即可进入到安装画面。在安装 画面1中选择界面语言后执行下一步。在安装画面2中,输入管理员的用户名及密码,数据库连接设置 (包括数据库类型,所在主机,所在端口,数据库用户,该用户的密码),海葵设置,点击“确定”结束安装。
 |
 |
|
| 安装画面1 | 安装画面2 |
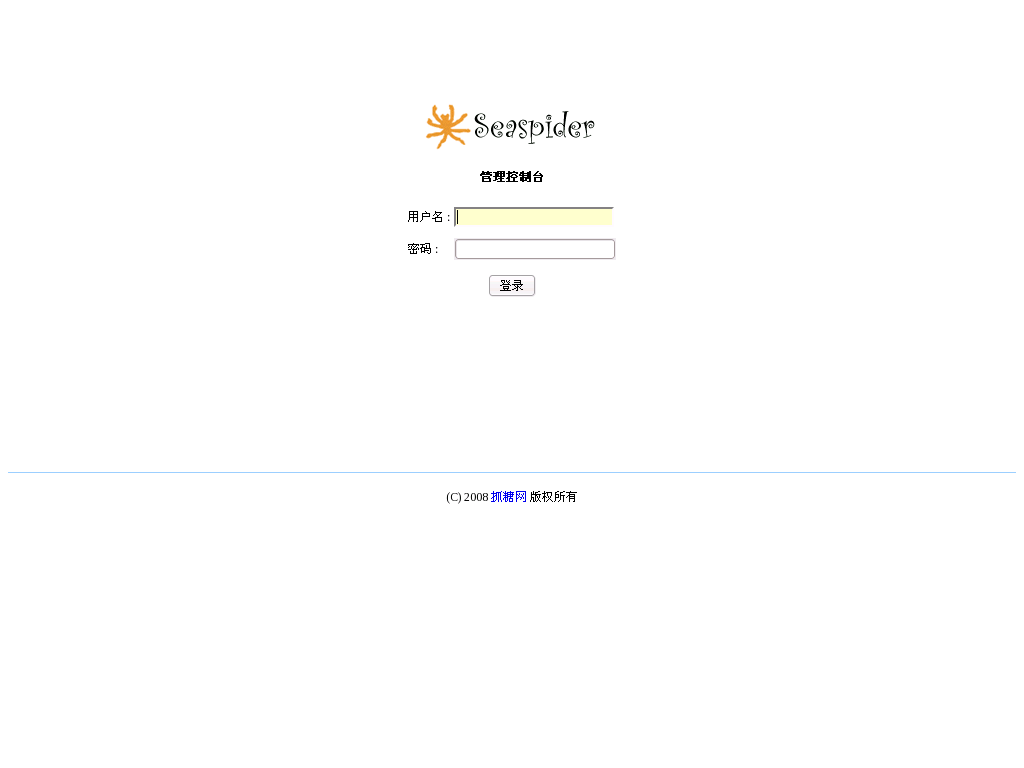
*登录海蛛*
海蛛安装成功后,通过浏览器访问海狗所在端口(如http://localhost:6070),使用安装时设置的用户名和 密码即可登录进海蛛控制台。
 |
| 登录画面 |
*海蛛控制台*
在海蛛控制台中,可以查看系统信息,进行任务管理,修改登录密码及退出系统。
一、系统信息
系统信息显示当前海蛛的版本、注册信息。如果未注册,用户需要提供MAC地址,该地址会显示在注册信息中。获得注册码后,点击“现在注册”, 输入注册码,完成注册。注册以后,需要重启一下海蛛。
 |
| 海蛛控制台 - 系统信息 |
二、任务管理
海蛛将数据抓取工作定义为任务,每项任务可以在设定的时间以多线程方式运行,最大线程数受限于任务 本身的设置。每个线程相当于传统意义的网络蜘蛛或爬虫。
 |
| 海蛛控制台 - 任务管理 |
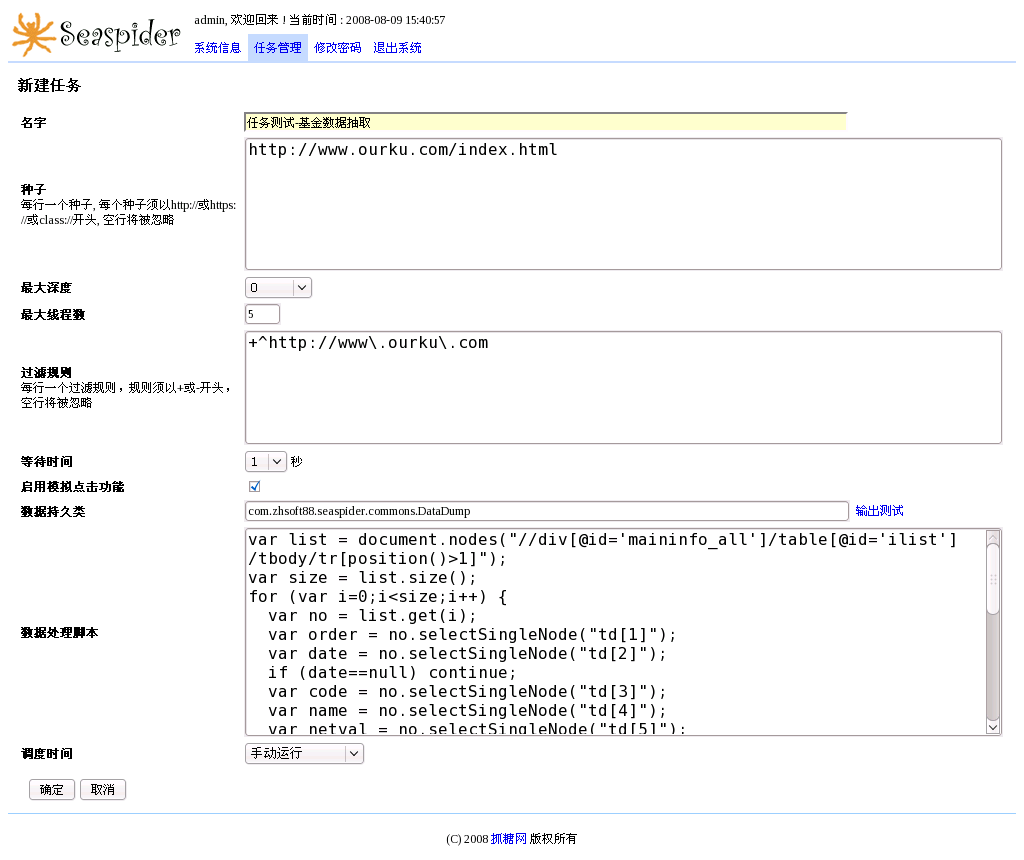
1、新建任务
点击“新建任务”即可进入新建任务画面。需要输入任务名称、种子、最大深度、最大线程数、过滤规则、 等待时间、数据持久类、数据处理脚本、调度时间等信息。
其中,过滤规则是每行一个规则,且此规则须以正则表达式RegExp方式书写。若未输入任何规则,则系统 默认有一个规则,即相同域名的链接均为合法链接。数据持久类由用户提供,须实现IDataPersist接口,打 成jar包存放到海蛛的userprovided目录下。系统提供了持久类DataDump,可供调试用。数据处理脚本由 Javascript写成。调度时间设定任务何时运行。
 |
 |
|
| 海蛛控制台 - 任务编辑示例1 | 海蛛控制台 - 任务编辑示例2 |
2、修改任务
点击“修改”即可修改相应的任务信息。
3、删除任务
点击“删除”即可删除任务,在真正删除以前,海蛛会确认一下。
当要新建的任务与现有某个任务有不少数据相同时,可以复制一下那个任务,在此基础上进行修改,这样做 比较省气点。
5、启动任务
任务为自动执行的任务时,点击“启动”后,此项任务将进入启动状态,时机一到就会执行。
6、停止任务
在任务启动或正在运行时,点击“停止”可中止任务的执行。
任务为手动运行时,点击“现在运行”就能执行这项任务。
三、修改密码
 |
| 海蛛控制台 - 修改密码 |
*蜘蛛编程接口*
在海蛛的任务中,需要编写数据处理脚本。数据处理脚本的功能是,分析当前抓取到的文档的内容,收集其中有用的 数据,调用任务指定的数据持久类将其持久化。注,自1.1.0版开始,海蛛取消了取下页链接脚本,进一步方便了垂直 搜索引擎开发者。
在脚本编程中,可使用系统内置的document对象,还可使用JAVA类(如功能特色三的示例代码中就用到了 java.util.HashMap这个JAVA类)。注,海蛛使用rhino来实现javascript支持,所有rhino支持的JAVA类海蛛同样支持。 系统内置的document对象是连接当前抓取到的文档与数据持久类的桥梁,它有以下属性:
(1) url 当前操作的URL (2) opnode 当前操作节点的XPATH
它提供以下方法:
A. String text(String xpath) 取指定节点的文本信息 B. String string(String xpath) 取指定节点及其子节点的文本信息 C. Node node(String xpath) 取一个节点 D. List<Node> nodes(String xpath) 取多个节点 E. void saveData(Map data) 保存收集到的数据
第1-4方法适用于分析文档内容,所传参数均为XPATH。第5个方法执行数据持久化的操作,传递的是Map形式(亦 即key/value)的数据。Node为dom4j的Node类,用户可在脚本中使用dom4j提供的各种方法。取多个节点文本信息 的代码:
var ns = document.nodes('//div[@id='text_sider']//div[1]/ol/li[@class='li_info']/span/a');
var text = '';
var size = ns.size();
for (var i=0;i<size;i++) {
text += ns.get(i).getText());
}
*编写网络蜘蛛程序* 海蛛的网络蜘蛛程序也即数据处理脚本。 开发准备: 1、安装JAVA开发环境eclipse 2、编译路径build path中加入dom4j的包和海蛛commons包(seaspider-*-commons.jar) 正式开发: 1、利用海葵获取数据源XML代码 2、编写JAVA代码,确保利用dom4j和XPATH能正确分析和保存数据 3、将JAVA程序转换为javascript程序,即将类型声明中有关类型都变成var,在javascript中所有变量都是无类型的。 如将int a改为var a,将Map map = new java.util.HashMap()改为var map = new java.util.HashMap()等。 4、在海蛛中新建任务,填入数据处理脚本,测试任务执行,查看结果。无误后可定义任务的执行时间,选择正式的 数据持久类,正式启动数据的抓取工作。
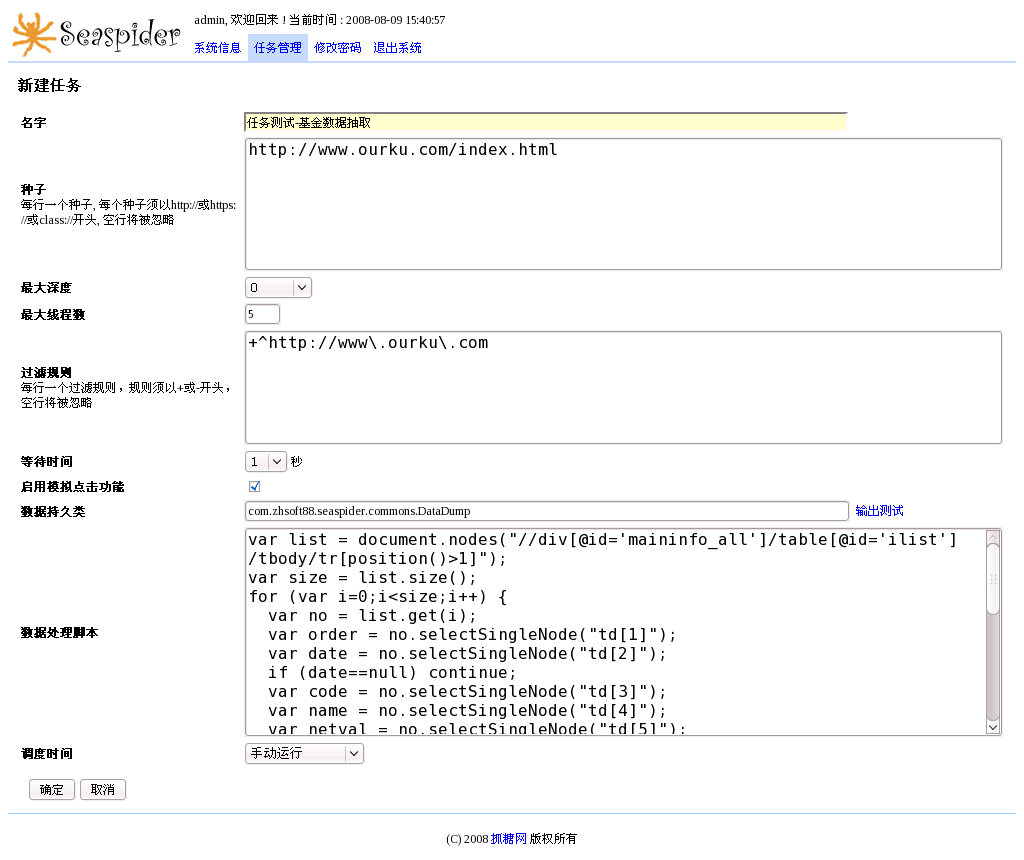 |
| 海蛛控制台 - ourku任务 |
种子: http://www.ourku.com/index.html
最大深度: 0
过滤规则: +^http://www\.ourku\.com
数据持久类: com.zhsoft88.seaspider.commons.DataDump
数据处理脚本:
var list = document.nodes("//div[@id='maininfo_all']/table[@id='ilist']/tbody/tr[position()>1]");
var size = list.size();
for (var i=0;i<size;i++) {
var no = list.get(i);
var order = no.selectSingleNode("td[1]");
var date = no.selectSingleNode("td[2]");
if (date==null) continue;
var code = no.selectSingleNode("td[3]");
var name = no.selectSingleNode("td[4]");
var netval = no.selectSingleNode("td[5]");
var totalval = no.selectSingleNode("td[6]");
var growval = no.selectSingleNode("td[7]");
var growrate = no.selectSingleNode("td[8]");
var map = new java.util.TreeMap();
map.put('order',order.getStringValue());
map.put('date',date.getStringValue());
map.put('code',code.getStringValue());
map.put('name',name.getStringValue());
map.put('netval',netval.getStringValue());
map.put('totalval',totalval.getStringValue());
map.put('growval',growval.getStringValue());
map.put('growrate',growrate.getStringValue());
document.saveData(map);
}