
Seadog is a spider system for vertical search. It employs the advanced technology of structural extraction by XSLT template. Seadog is not only suitable for vertical search engine, but also suitable for web data mining area...
The spider of general vertical search engine takes web data as character streams, extract data by regular expression, parsing speed is lower, data accuracy is lower too. A little modification of one page can affect extract results gravely. For example, if you want to extract data in DIV element which ID attribute value is 'a', the element can be writen as <div id="a">, or <div id='a'>, or <div id=a> ... The regular expression you wrote should match all of these pattern, otherwise you'll get no data. At the same time, you must select the correct close node - </div>, maybe the DIV element has another DIV elements as its children. You should consider these conditions more carefully.
On the contrary, these problems disappeared in Seadog. Using XPATH //div[@id='a'], you'll get content of DIV element, which ID attribute value is 'a'. It's simple, convenient and comprehensible. Seadog supports XPATH 2.0, XSLT 2.0 and other XML technologies. It's extensibility is better than regular expression extraction. To structurize web page data, Seadog uses Seastar - the advanced web structural tool developed by zhuatang.com.
Featured functions
1.Provides web interface
After Seadog starts up, user can visit http://localhost:6474 by browser. Seadog's default listen port is 6474, user can modify it. When logged in Seadog, use may look up system information, manage persistent class, manage task, and so on. Most of Seadog's operations are done through browser, it's simple and easy.
2.Various schedule time
Seadog provides various schedule time for task: run manually, run every N minutes, run every N hours, run at HH:MM every day...
Every task has its schedule time. Seadog can run the task at specific time after task starts.
3.Support various databases
Seadog supports PostgreSQL ,MySQL,Oracle,SQL Server and embedded database HSQLDB. HSQLDB has already embedded in Seadog, it's suitable for user testing and light crawl task. no need for install it.
4.Storing extracted data to database automatically
Based on user provided persistent class (pclass) and XSLT template, Seadog extracts data from web page, stores these data to database automatically.
5.Collecting URL seeds automatically
When executing crawl tasks, Seadog collects URL seeds automatically, user can use url filter rules to filter those uninterested urls. To collect hidden URLs (not written as <a href="xxx">), Seadog employs Seed Extraction Template (SET) user provided.
6.Extract by stages
There are some data that cannot be extracted in one stage, for example, search results from google. At first, user collect result urls. Second, open these urls, extract some data. These works fine in Seadog.
7.Template language using XSLT
Seadog use XSLT template to extract data from web page, it's simple, user friendly, and extensible.
Want to make a vertical search engine? Just use Seadog.
Seadog - for vertical search engine made easy!
seadog-1.2-installer.exe
(For Windows)
seadog-1.2-fc9.tar.gz
(For Fedora Core 9 Linux)
seadog-1.2-el5.tar.gz
(For RedHat EL 5/CentOS Linux)
*Install Help*
WINDOWS: Double click Seadog installer, start Seadog service.
LINUX: unpack Seadog package, execute "bin/seadog start", start Seadog service.
After Seadog started, please open your browser, visit the port Seadog used, for example, http://localhost:6474, continue installing - select language, administrator name and password, database settings ...
*Login*
After completed install process, please open your browser, visit the port Seadog used, for example, http://localhost:6474, input administrator name and password, click "OK", login Seadog.
Seadog Console
In Seadog console, you can look up system information, manage persistent class, manage task, change login name and password.
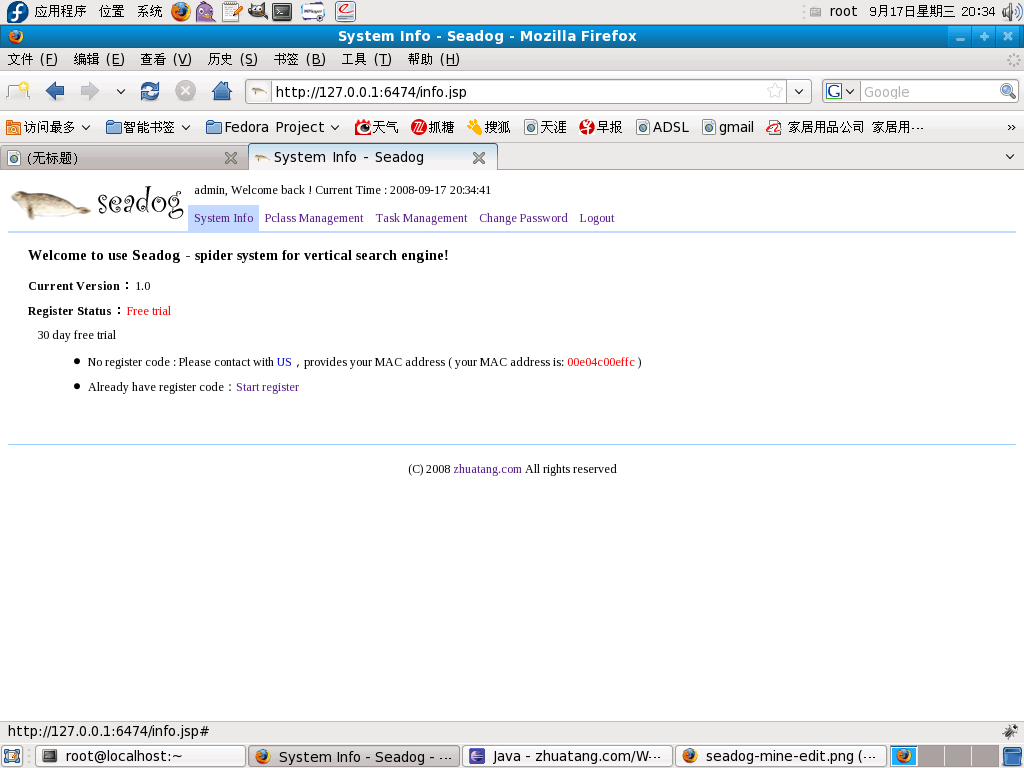
1.System Information
System information shows Seadog's version and register status. If Seadog is not registered, user must provide MAC address which displayed in System information. After you got register code, click "register now" to register Seadog.
 |
| Seadog Console - System Information |
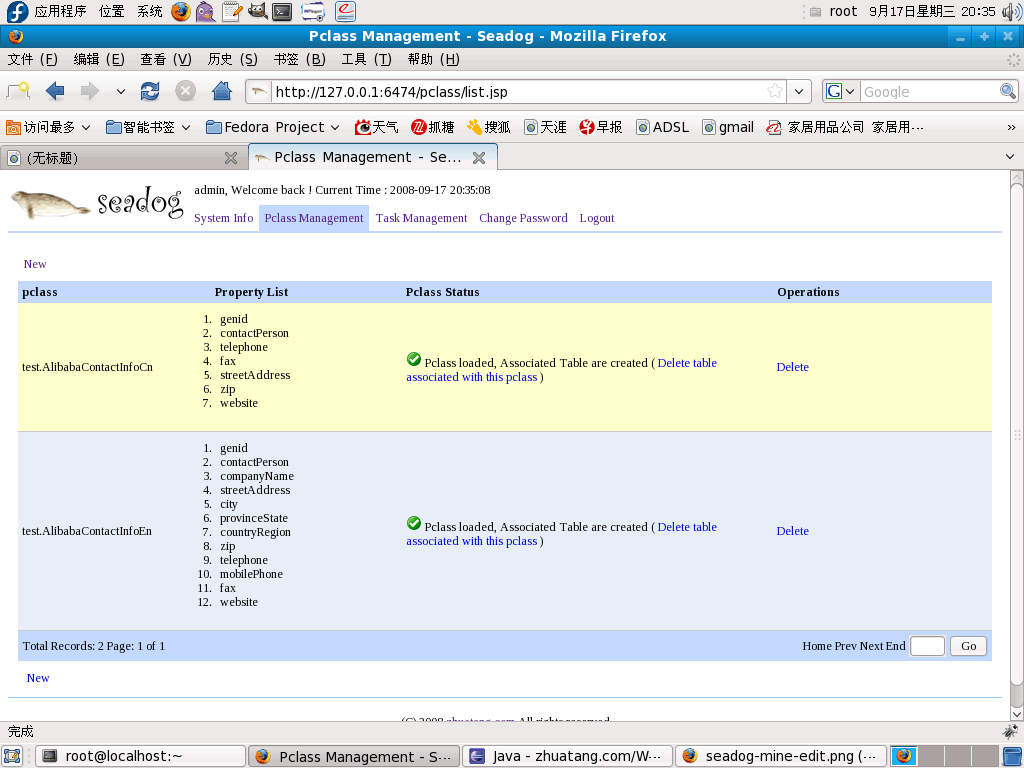
2.Pclass Management
Pclass - persistent class, is java class to store data. Every pclass maps to a database table in Seadog, user can create or delete this table.
 |
| Seadog Console - Pclass Management |
Pclass Import
1. pack persistent class to a .jar file. 2. click "New", choose this jar file. 3. select the persist class name. 4. click "OK" to import it, then you should restart Seadog for using this pclass.
Three properties that pclass must have
1) id : unique ID, generated by Seadog.
private Long id;
2) ctime : create time, generated by Seadog.
@TableColumn private Timestamp ctime;
3) genid : unique ID, specified by user in XSLT template.
@TableColumn(unique=true) private String genid;
Pclass development
1) Decide what you want to store
2) Create JAVA project, reference Seadog's library(lib/seadog-1.2-core.jar)
3) Create a JAVA class, adds id,ctime,genid and other properties, annotates each property except id. Default value of annotation: notNull=true, unique=false.
4) Adds getter/setter methods
5) Export this class to jar file, import it in Seadog.
Pclass example 1 - alibaba.com english contact information AlibabaContactInfoEn.java Download
package test;
import java.sql.Timestamp;
import com.zhsoft88.commons.db.TableColumn;
/**
* alibaba contact info en
* @author zhsoft88
*
* @since 2008-9-21
*/
public class AlibabaContactInfoEn {
@TableColumn(unique=true)
private Long id;
@TableColumn(unique=true)
private String genid;
@TableColumn
private Timestamp ctime;
@TableColumn
private String contactPerson;
@TableColumn
private String companyName;
@TableColumn
private String streetAddress;
@TableColumn
private String city;
@TableColumn
private String provinceState;
@TableColumn
private String countryRegion;
@TableColumn(notNull=false)
private String zip;
@TableColumn(notNull=false)
private String telephone;
@TableColumn(notNull=false)
private String mobilePhone;
@TableColumn(notNull=false)
private String fax;
@TableColumn(notNull=false)
private String website;
public AlibabaContactInfoEn() {
// TODO Auto-generated constructor stub
}
public Long getId() {
return id;
}
private void setId(Long id) {
this.id = id;
}
public String getGenid() {
return genid;
}
public void setGenid(String genid) {
this.genid = genid;
}
public Timestamp getCtime() {
return ctime;
}
public void setCtime(Timestamp ctime) {
this.ctime = ctime;
}
public String getContactPerson() {
return contactPerson;
}
public void setContactPerson(String contactPerson) {
this.contactPerson = contactPerson;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public String getStreetAddress() {
return streetAddress;
}
public void setStreetAddress(String streetAddress) {
this.streetAddress = streetAddress;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getProvinceState() {
return provinceState;
}
public void setProvinceState(String provinceState) {
this.provinceState = provinceState;
}
public String getCountryRegion() {
return countryRegion;
}
public void setCountryRegion(String countryRegion) {
this.countryRegion = countryRegion;
}
public String getZip() {
return zip;
}
public void setZip(String zip) {
this.zip = zip;
}
public String getTelephone() {
return telephone;
}
public void setTelephone(String telephone) {
this.telephone = telephone;
}
public String getMobilePhone() {
return mobilePhone;
}
public void setMobilePhone(String mobilePhone) {
this.mobilePhone = mobilePhone;
}
public String getFax() {
return fax;
}
public void setFax(String fax) {
this.fax = fax;
}
public String getWebsite() {
return website;
}
public void setWebsite(String website) {
this.website = website;
}
}
Pclass example 2 - alibaba.com chinese contact information AlibabaContactInfoCn.java Download
package test;
import java.sql.Timestamp;
import com.zhsoft88.commons.db.TableColumn;
/**
* alibaba contact info cn
* @author zhsoft88
*
* @since 2008-9-21
*/
public class AlibabaContactInfoCn {
@TableColumn(unique=true)
private Long id;
@TableColumn(unique=true)
private String genid;
@TableColumn
private Timestamp ctime;
@TableColumn
private String contactPerson;
@TableColumn(notNull=false)
private String telephone;
@TableColumn(notNull=false)
private String fax;
@TableColumn(notNull=false)
private String streetAddress;
@TableColumn(notNull=false)
private String zip;
@TableColumn(notNull=false)
private String website;
public AlibabaContactInfoCn() {
// TODO Auto-generated constructor stub
}
public Long getId() {
return id;
}
private void setId(Long id) {
this.id = id;
}
public String getGenid() {
return genid;
}
public void setGenid(String genid) {
this.genid = genid;
}
public Timestamp getCtime() {
return ctime;
}
public void setCtime(Timestamp ctime) {
this.ctime = ctime;
}
public String getContactPerson() {
return contactPerson;
}
public void setContactPerson(String contactPerson) {
this.contactPerson = contactPerson;
}
public String getTelephone() {
return telephone;
}
public void setTelephone(String telephone) {
this.telephone = telephone;
}
public String getFax() {
return fax;
}
public void setFax(String fax) {
this.fax = fax;
}
public String getStreetAddress() {
return streetAddress;
}
public void setStreetAddress(String streetAddress) {
this.streetAddress = streetAddress;
}
public String getZip() {
return zip;
}
public void setZip(String zip) {
this.zip = zip;
}
public String getWebsite() {
return website;
}
public void setWebsite(String website) {
this.website = website;
}
}
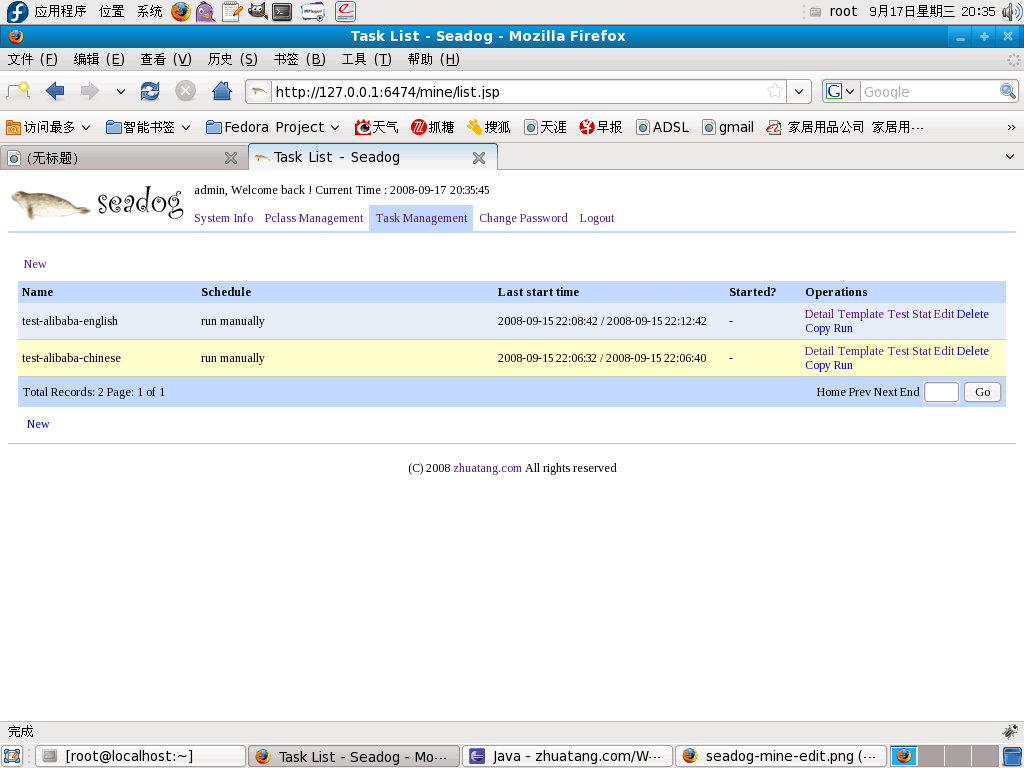
3. Task Management
In Seadog, every data extraction work should be defined as a task, every task runs in multi-threaded way, maximum thread defined in task configuration. Each task thread just like conventional web spider or crawler.
 |
| Seadog Console - Task Management |
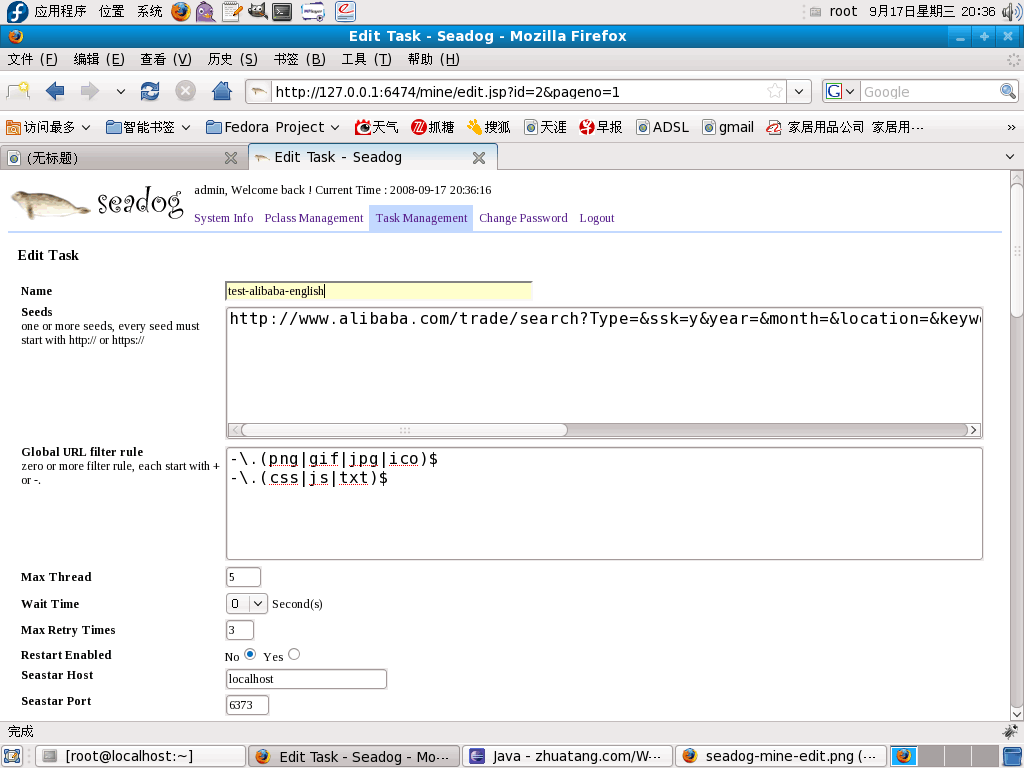
1) New task
Click "New" to create new task. User should input:
must be unique name.
Input one or more seed URL, seperated by space. Every URL must starts with http:// or https://.
This can has zero or more url filter rules, each rule must starts with + or -. These rules are effective in all extraction stages.
Maximum thread that task employs.
Seadog will sleep the specific time before starting to crawl web page
If crawling failed, Seadog can do another attempt if allowed.
Each task has at least one crawling stage. Each stage has following properties:
required. Must use XSLT 2.0, refer to pclass name that Seadog loaded and it's table created. Seed pclass name is _SEED_. Referring format:
<pclass name="pclass name"> <key1>...</value1> <key2>...</value2> ...... </pclass>
Optional. Zero or more URL filters, each filter written by regular expression, starting with + or -, + stands for allow, - stands for disallow.
Optional. Use this template collect seed URLs that cannot be identified by href attribute. Must use _SEED_ as pclass name in order to store link.
Optional. Zero or more URLs for validating template. If you wanna comment some test URLs, please add # ahead of URL.
2) Edit task
 |
| Seadog Console - Edit task |
3) Detail
Show the detail information of task.
4) Test
Validate template.
5) Status
Current task's status.
6) Copy
Create new task by copying.
7) Run Now
Run manually task right now.
8) Start
Start task which will execute at specific time.
9) Stop
Stop task running.
10) Pause
When task is running, click "Pause" to pause running.
11) Resume
Resume task paused.
4. Change password
Change login name and password.
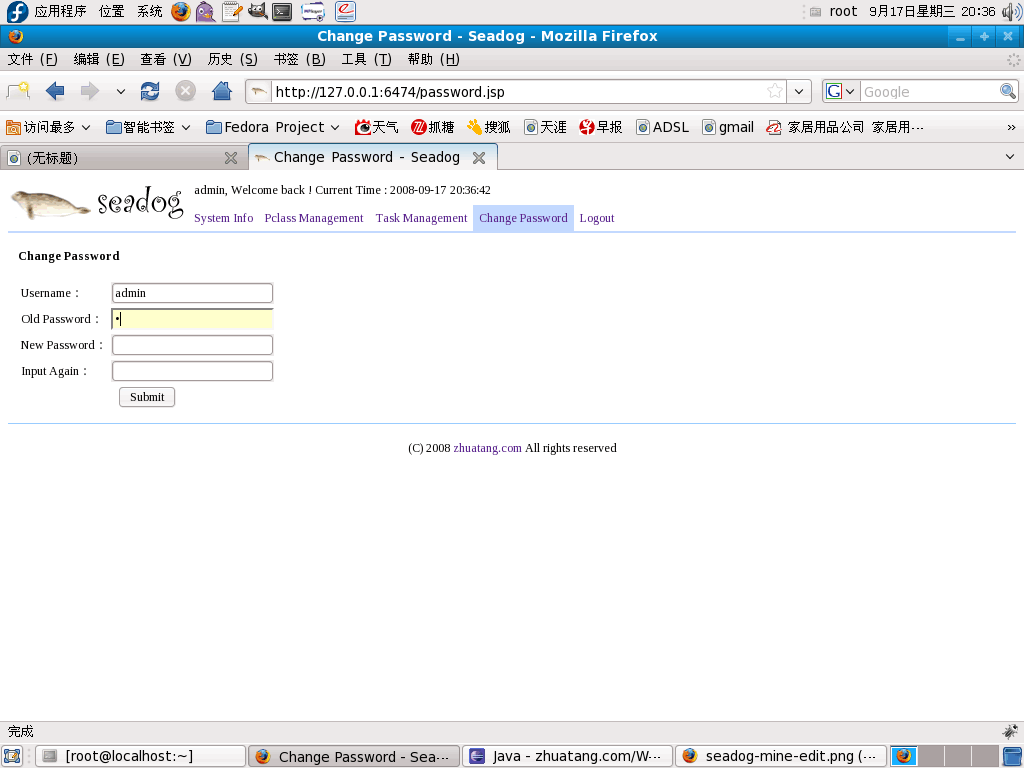 |
| Seadog Console - Change password |
Task example 1: crawl company contact information from alibaba english search results
test-alibaba-english
http://www.alibaba.com/trade/search/2i1ptyfchms/Shoes.html
-\.(gif|jpg|png|txt|css|js)$
5
0
3
false
localhost
6373
run manually
<xsl:for-each select="//div[starts-with(@class,'itemBox')]/div[@class='box4']/h2/a/@href"> <pclass name="_SEED_"> <url><xsl:value-of select="resolve-uri(.,$baseuri)"/></url> </pclass> </xsl:for-each>
1
http://www.alibaba.com/suppliers/Shoes/2.html http://www.alibaba.com/suppliers/Shoes/10.html
<xsl:if test="normalize-space(//table[@class='tables data']//tr[starts-with(child::*[1],'Contact Person:')]/child::*[2]) != ''"> <xsl:for-each select="//table[@class='tables data']"> <pclass name="test.AlibabaContactInfoEn"> <genid><xsl:value-of select="$baseuri"/></genid> <companyName><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Company Name:')]/child::*[2])"/></companyName> <contactPerson><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Contact Person:')]/child::*[2]//span[@class='contactName'])"/></contactPerson> <streetAddress><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Street Address:')]/child::*[2])"/></streetAddress> <city><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'City:')]/child::*[2])"/></city> <provinceState><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Province/State:')]/child::*[2])"/></provinceState> <countryRegion><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Country/Region:')]/child::*[2])"/></countryRegion> <zip><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Zip:')]/child::*[2])"/></zip> <telephone><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Telephone:')]/child::*[2])"/></telephone> <mobilePhone><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Mobile Phone:')]/child::*[2])"/></mobilePhone> <fax><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Fax:')]/child::*[2])"/></fax> <website><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Website:')]/child::*[2])"/></website> </pclass> </xsl:for-each> </xsl:if>
+/contactinfo.html$
1
http://shuangstar.en.alibaba.com/contactinfo.html http://susantrade.en.alibaba.com/contactinfo.html http://www.alibaba.com/member/priceshoesnorbert/contactinfo.html
Task example 2: crawl company contact information from alibaba chinese search results
test-alibaba-chinese
http://search.china.alibaba.com/search/company_search.htm?tracelog=po_searchcompany_select_bf&tracelog=&keywords=%BC%D2%BE%D3%D3%C3%C6%B7&submit=+%D6%D8%D0%C2%CB%D1%CB%F7+
-\.(gif|jpg|png|txt|css|js)$
5
0
3
false
localhost
6373
run manually
<xsl:for-each select="//div[@class='offer']"> <pclass name="_SEED_"> <url><xsl:value-of select="resolve-uri(.//div[@class='info']/span/a/@href,$baseuri)"/></url> </pclass> </xsl:for-each>
+http://search.china.alibaba.com/company/%E5%AE%B6%E5%B1%85%E7%94%A8%E5%93%81/(\d{1,}).html
1
http://search.china.alibaba.com/company/%E5%AE%B6%E5%B1%85%E7%94%A8%E5%93%81/2.html http://search.china.alibaba.com/company/%E5%AE%B6%E5%B1%85%E7%94%A8%E5%93%81/8.html
<xsl:for-each select="//div[@class='contacts'][1]"> <pclass name="test.AlibabaContactInfoCn"> <genid><xsl:value-of select="$baseuri"/></genid> <contactPerson><xsl:value-of select=".//div[@class='mp_r']//a[1]"/></contactPerson> <telephone><xsl:value-of select="substring-after(./ul/li[starts-with(.,'电')],':')"/></telephone> <fax><xsl:value-of select="substring-after(./ul/li[starts-with(.,'传')],':')"/></fax> <streetAddress><xsl:value-of select="substring-after(./ul/li[starts-with(.,'地')],':')"/></streetAddress> <zip><xsl:value-of select="substring-after(./ul/li[starts-with(.,'邮')],':')"/></zip> <website><xsl:value-of select="substring-after(./ul/li[starts-with(.,'公')],':')"/></website> </pclass> </xsl:for-each>
+/contact/
<xsl:variable name="tmp">'</xsl:variable> <pclass name="_SEED_"> <url><xsl:value-of select="resolve-uri(substring-before(substring-after(//li[starts-with(@class,'headerMenuLi') and contains(.,'联系方式') and starts-with(@onclick,'window.location.href=') ]/@onclick,$tmp),$tmp),$baseuri)"/></url> </pclass>
1
http://chsp.cn.alibaba.com/athena/contact/chsp.html http://jinmaiqxh.cn.alibaba.com/athena/contact/jinmaiqxh.html http://cmgsguocj.cn.alibaba.com/athena/contact/cmgsguocj.html