
海狗是一款垂直搜索专用网络蜘蛛系统,它应用了领先的结构化抽取技术,采用XSLT构造抽取模板。海狗不仅适用于垂直搜索引擎的数据抓取, 更可适用于网络信息采集等领域,功能非常强大。
一般的垂直搜索引擎的网络蜘蛛,视网页数据为字符流,采用正则表达式模板来串行抽取网页数据,其存在的问题是效率低,抽取精度不高, 网页改动对抽取的影响比较大,正则表达式极可能要重写,否则数据则抽取不到。譬如说要抽取id属性值为a的div节点内容, 其书写形式可以是<div id="a">,也可以是<div id='a'>,还可以是<div id=a>等, 正则表达式不易书写。如果在id属性前面或后面添加一个或多个其它的属性,就更不好办了。使用正则抽取还有个大难题, 就是闭合节点</div>的选择事关重大,因为此div的内容中还可能嵌套其它div节点。如果没选准确,或者网页源码稍有改动, 就得不到正确的数据了。
而这些问题,对于采用结构化抽取手段的海狗来说,根本就不是问题了。使用XPATH指令//div[@id='a'] 即可得到id属性值为a的div节点内容,不必担心其书写形式,也不必考虑闭合节点的位置。海狗支持XPATH2.0,XSLT2.0等最新的XML技术, 可利用语言的特性来解决数据抽取、数据格式化等问题,并且可以扩展。海狗是使用海星来结构化网页的, 在此基础上抽取数据是非常简单的。
海狗功能特色
一、提供WEB管理接口,操作方便
海狗启动后,用户可用浏览器访问http://localhost:6474(注:6474为默认端口,用户也可修改此端口号),登录后 便可进行查看系统信息、管理持久类、管理任务和修改登录用户名及密码的工作。任务管理包括新建、修改、复制、启动、停止等 项。一切都是通过浏览器来进行,非常简单。
二、蜘蛛程序运行时间多样,选择灵活
为了适应各种情况,海狗提供了多种运行时间选择:手动运行,每隔X分钟,每隔X小时,每天X时X分,每周周XX时X 分,每月X日X点X分,每年X月X日X时X分。这些时间选择,完全满足了数据抓取任务的要求。
每项任务都可选择自己的运行时间,任务启动后,海狗会在合适的时刻运行此项任务,执行数据的抓取工作,经由用 户提供的持久类,将数据保存起来。
三、支持多种数据库
海狗支持通用的数据库PostgreSQL,MySQL,Oracle,SQL Server, 支持嵌入式数据库HSQLDB。HSQLDB已内置到海狗中, 勿需另外安装,方便用户测试和执行轻量级的抓取任务。如果抓取任务多,并发运行的线程多,就需要采用PostgreSQL数据库。注意,数据库均需采用utf8编码,这样才能保证输入汉字不会出现乱码现象。
四、抽取数据直接入库
基于用户提供的持久类(pclass)和XSLT模板,海狗能将抽取到的数据直接存到数据库中,方便用户管理。
五、系统能自动收集URL种子
在海狗运行抓取任务过程中,URL种子是由系统自动采集的,勿需用户参与,并且用户可以编写过滤规则,过滤掉不需要的种子。 另外,为了适应某些网页的URL链接不用<a href="xxx">来书写,导致系统采集不到的问题,海狗提供了相应接口, 通过执行用户自己书写的种子抽取模板,能采集到这些隐藏的种子,从而抓取到相应的数据。
六、可分步进行抽取工作
某些数据是不能马上取到的,它需要经过多个操作步骤才能得到最终结果页面,譬如说抽取搜索引擎的搜索结果的数据: 第一步要求得到结果列表中的超链接,第二步打开这些链接,抽取所需的数据。这一切在海狗中均可轻松实现。
七、模板采用XSLT语言
海狗使用结构化的抽取手段,模板需用XSLT语言书写,用户可充分利用语言的特性来抽取数据,格式化数据。
想做一个垂直搜索引擎吗?使用海狗吧,它让您如虎添翼!
海狗,让垂直搜索更简单!
seadog-1.2-installer.exe
(适用于Windows系统)
seadog-1.2-fc9.tar.gz
(适用于Fedora Core 9兼容的Linux系统)
seadog-1.2-el5.tar.gz
(适用于RedHat EL 5/CentOS兼容的Linux系统)
*安装海狗*
WINDOWS: 双击海狗安装程序,最后启动海狗服务。
LINUX: 解压海狗安装包,执行bin/seadog start,启动海狗服务。
海狗启动后,通过浏览器访问海狗所在端口(如http://localhost:6474)即可进入到安装画面。在安装 画面1中选择界面语言后执行下一步。在安装画面2中,输入管理员的用户名及密码,数据库连接设置 (包括数据库类型,所在主机,所在端口,数据库用户,该用户的密码),点击“确定”结束安装。
*登录海狗*
海狗安装成功后,通过浏览器访问海狗所在端口(如http://localhost:6474),使用安装时设置的用户名和 密码即可登录进海狗控制台。
*海狗控制台*
在海狗控制台中,可以查看系统信息,管理持久类,进行任务管理,修改登录密码及退出系统。
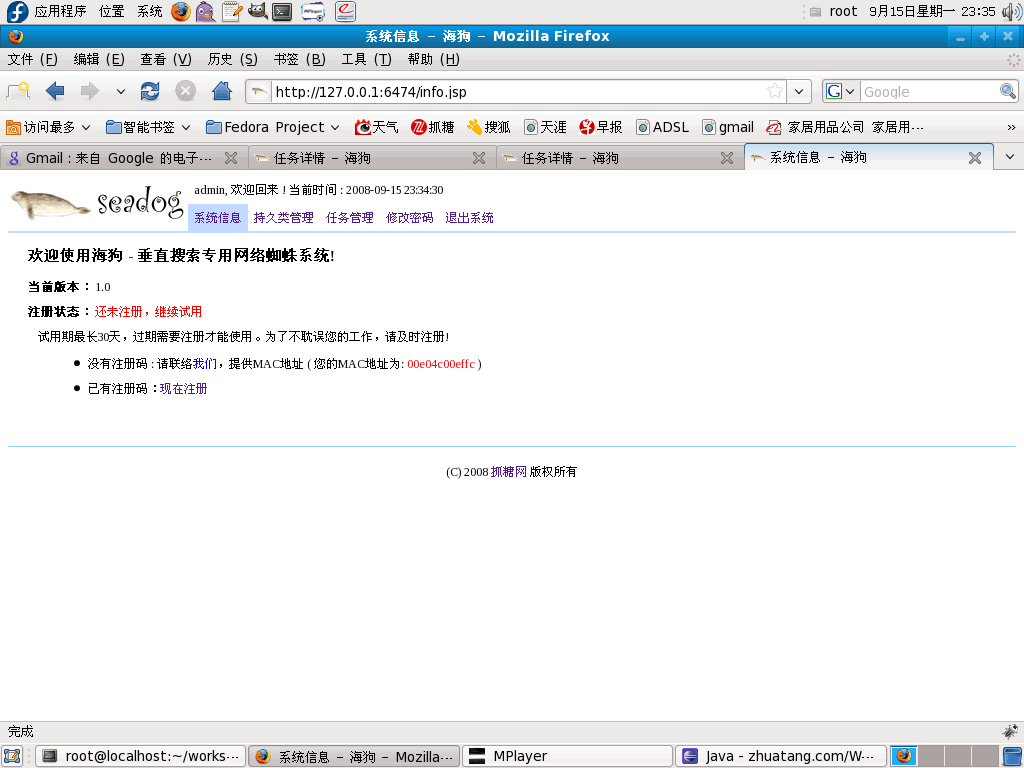
一、系统信息
系统信息显示当前海狗的版本、注册信息。如果未注册,用户需要提供MAC地址,该地址会显示在注册信息中。获得注册码后,点击“现在注册”, 输入注册码,完成注册。注册以后,需要重启一下海狗。
 |
| 海狗控制台 - 系统信息 |
二、持久类管理
持久类(pclass)是用以保存抽取数据的JAVA类。每个持久类在海狗中会映射为单独的数据表,用户可以创建或删除此表, 可在数据库中查询此表的数据。
 |
| 海狗控制台 - 持久类管理 |
持久类导入
首先要将做好的持久类打包(JAR格式),然后点击“新建”,选定此包,在下一步中选定正确的JAVA类,点击“完成”即可。 持久类导入后,必须重启一下海狗,这样持久类才能为系统所用,才能创建相应的数据表。创建了数据表后,就可以在XSLT模板中 引用这个持久类名了。
持久类必须含有的三个属性
1) id : 为数据唯一ID值,由系统自动设定。
private Long id;
2) ctime : 为数据创建时间,由系统自动设定。
@TableColumn private Timestamp ctime;
3) genid : 为数据唯一ID值,须由用户在XSLT模板中编程设定
@TableColumn(unique=true) private String genid;
持久类开发过程
1) 确定你要保存些什么数据
2) 新建JAVA项目,引用海狗的库(lib/seadog-1.2-core.jar)
3) 新建JAVA类,添加持久类必须的三个属性(id,ctime,genid),再添加其它属性。注意,除id外,每个属性均须使用@TableColumn注释。 注释默认值: notNull=true, unique=false . notNull表示属性值是否要求非空,unique表示属性值是否要求唯一。
4) 添加各个属性的getter/setter方法
5) 导出此类为JAR文件,这样就可以在海狗中引用了
持久类示例一 阿里巴巴企业英文联系信息 AlibabaContactInfoEn.java 下载
package test;
import java.sql.Timestamp;
import com.zhsoft88.commons.db.TableColumn;
/**
* alibaba contact info en
* @author zhsoft88
*
* @since 2008-9-21
*/
public class AlibabaContactInfoEn {
@TableColumn(unique=true)
private Long id;
@TableColumn(unique=true)
private String genid;
@TableColumn
private Timestamp ctime;
@TableColumn
private String contactPerson;
@TableColumn
private String companyName;
@TableColumn
private String streetAddress;
@TableColumn
private String city;
@TableColumn
private String provinceState;
@TableColumn
private String countryRegion;
@TableColumn(notNull=false)
private String zip;
@TableColumn(notNull=false)
private String telephone;
@TableColumn(notNull=false)
private String mobilePhone;
@TableColumn(notNull=false)
private String fax;
@TableColumn(notNull=false)
private String website;
public AlibabaContactInfoEn() {
// TODO Auto-generated constructor stub
}
public Long getId() {
return id;
}
private void setId(Long id) {
this.id = id;
}
public String getGenid() {
return genid;
}
public void setGenid(String genid) {
this.genid = genid;
}
public Timestamp getCtime() {
return ctime;
}
public void setCtime(Timestamp ctime) {
this.ctime = ctime;
}
public String getContactPerson() {
return contactPerson;
}
public void setContactPerson(String contactPerson) {
this.contactPerson = contactPerson;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public String getStreetAddress() {
return streetAddress;
}
public void setStreetAddress(String streetAddress) {
this.streetAddress = streetAddress;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getProvinceState() {
return provinceState;
}
public void setProvinceState(String provinceState) {
this.provinceState = provinceState;
}
public String getCountryRegion() {
return countryRegion;
}
public void setCountryRegion(String countryRegion) {
this.countryRegion = countryRegion;
}
public String getZip() {
return zip;
}
public void setZip(String zip) {
this.zip = zip;
}
public String getTelephone() {
return telephone;
}
public void setTelephone(String telephone) {
this.telephone = telephone;
}
public String getMobilePhone() {
return mobilePhone;
}
public void setMobilePhone(String mobilePhone) {
this.mobilePhone = mobilePhone;
}
public String getFax() {
return fax;
}
public void setFax(String fax) {
this.fax = fax;
}
public String getWebsite() {
return website;
}
public void setWebsite(String website) {
this.website = website;
}
}
持久类示例二 阿里巴巴企业中文联系信息 AlibabaContactInfoCn.java 下载
package test;
import java.sql.Timestamp;
import com.zhsoft88.commons.db.TableColumn;
/**
* alibaba contact info cn
* @author zhsoft88
*
* @since 2008-9-21
*/
public class AlibabaContactInfoCn {
@TableColumn(unique=true)
private Long id;
@TableColumn(unique=true)
private String genid;
@TableColumn
private Timestamp ctime;
@TableColumn
private String contactPerson;
@TableColumn(notNull=false)
private String telephone;
@TableColumn(notNull=false)
private String fax;
@TableColumn(notNull=false)
private String streetAddress;
@TableColumn(notNull=false)
private String zip;
@TableColumn(notNull=false)
private String website;
public AlibabaContactInfoCn() {
// TODO Auto-generated constructor stub
}
public Long getId() {
return id;
}
private void setId(Long id) {
this.id = id;
}
public String getGenid() {
return genid;
}
public void setGenid(String genid) {
this.genid = genid;
}
public Timestamp getCtime() {
return ctime;
}
public void setCtime(Timestamp ctime) {
this.ctime = ctime;
}
public String getContactPerson() {
return contactPerson;
}
public void setContactPerson(String contactPerson) {
this.contactPerson = contactPerson;
}
public String getTelephone() {
return telephone;
}
public void setTelephone(String telephone) {
this.telephone = telephone;
}
public String getFax() {
return fax;
}
public void setFax(String fax) {
this.fax = fax;
}
public String getStreetAddress() {
return streetAddress;
}
public void setStreetAddress(String streetAddress) {
this.streetAddress = streetAddress;
}
public String getZip() {
return zip;
}
public void setZip(String zip) {
this.zip = zip;
}
public String getWebsite() {
return website;
}
public void setWebsite(String website) {
this.website = website;
}
}
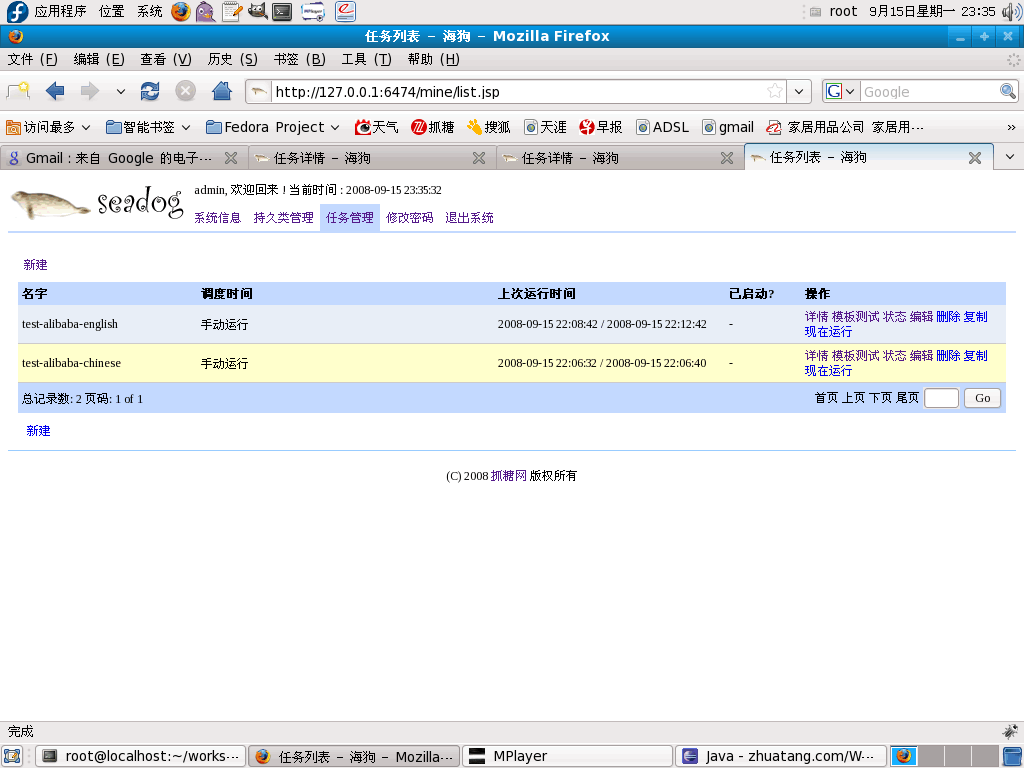
三、任务管理
海狗将数据抓取工作定义为任务,每项任务可以在设定的时间以多线程方式运行,最大线程数受限于任务 本身的设置。每个线程相当于传统意义的网络蜘蛛或爬虫。可执行的操作如下:
 |
| 海狗控制台 - 任务管理 |
1) 新建
点击“新建”即可进入新建任务画面。需要输入如下内容:
必须唯一,不能重复。
输入一个或多个种子,以空格分隔。每个种子须以http://或https://开头。
此项可为空,亦可有一个或多个过滤规则,规则需用正则表达式书写,使用+或-作前缀,+表示允许,-表示过滤。 此规则将应用于全部抽取步骤中。
海狗能多线程执行抓取任务,此项决定最多有几个抓取线程。
每项任务在抓取前,都可等待一段时间,这样可以缓冲一下对服务器的压力。
在抓取失败时,海狗可以再尝试多次,此项决定尝试的次数。
若允许,海狗能在上次抓取过程的基础上继续执行,否则就重新开始。
决定任务在什么时间运行。
任务最少有一个抽取步骤。每个抽取步骤有如下几项:
此为必填项。须采用XSLT2.0语言描述,在其中引用系统装入的持久类名。种子持久类为_SEED_。引用格式为:
<pclass name="持久类名"> <属性1>...</值1> <属性2>...</值2> ...... </pclass>
此项可为空,亦可有一个或多个过滤规则,规则需用正则表达式书写,使用+或-作前缀,+表示允许,-表示过滤。 这些规则用于过滤当前操作步骤所发现的新的种子。
用此模板收集那些无法用href属性来标识的超链接。须引用种子持久类来保存所发现的链接。
此项可为空,亦可有一个或多个链接,供验证模板用。若想注释掉某链接,可在此链接前加#。
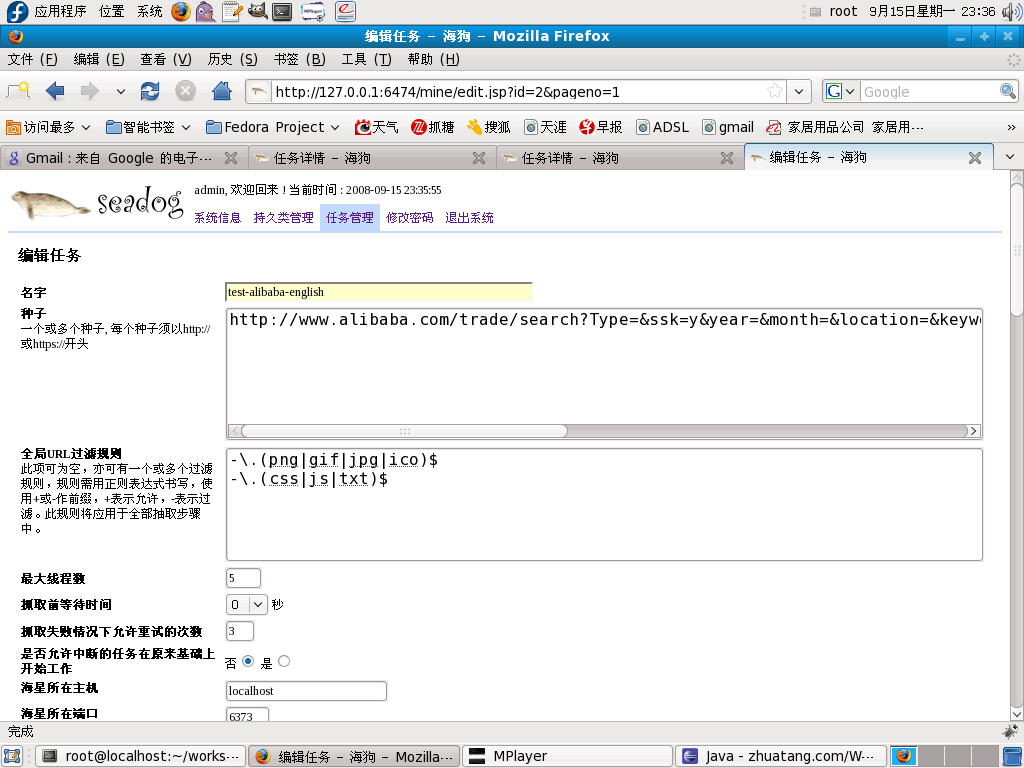
2) 编辑
修改当前任务。
 |
| 海狗控制台 - 编辑任务 |
3) 详情
显示任务的具体内容供查看。
4) 模板测试
测试模板执行情况。若抽取不到任何数据,有可能是模板写得有问题。
5) 状态
显示当前或上次任务执行的情况。
6) 复制
将当前任务复制一份,一般用于在此任务定义基础上稍加修改,成为一个新任务。
7) 现在运行
任务为手动运行时,点击“现在运行”就能执行这项任务。
8) 启动
任务为自动执行的任务时,点击“启动”后,此项任务将进入启动状态,时机一到就会执行。
9) 停止
在任务启动或正在运行时,点击“停止”可中止任务的执行。
10) 暂停
在任务正在运行时,点击“暂停”可暂停任务运行。
11) 继续
在任务处在暂停时,点击“继续”可让此任务继续运行。
四、修改密码
在此界面下可修改登录海狗控制台的用户名及密码。
 |
| 海狗控制台 - 修改密码 |
任务示例一:抓取阿里巴巴英文搜索结果中相关企业的联系信息
test-alibaba-english
http://www.alibaba.com/trade/search/2i1ptyfchms/Shoes.html
-\.(gif|jpg|png|txt|css|js)$
5
0
3
否
localhost
6373
手动运行
<xsl:for-each select="//div[starts-with(@class,'itemBox')]/div[@class='box4']/h2/a/@href"> <pclass name="_SEED_"> <url><xsl:value-of select="resolve-uri(.,$baseuri)"/></url> </pclass> </xsl:for-each>
1
http://www.alibaba.com/suppliers/Shoes/2.html http://www.alibaba.com/suppliers/Shoes/10.html
<xsl:if test="normalize-space(//table[@class='tables data']//tr[starts-with(child::*[1],'Contact Person:')]/child::*[2]) != ''"> <xsl:for-each select="//table[@class='tables data']"> <pclass name="test.AlibabaContactInfoEn"> <genid><xsl:value-of select="$baseuri"/></genid> <companyName><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Company Name:')]/child::*[2])"/></companyName> <contactPerson><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Contact Person:')]/child::*[2]//span[@class='contactName'])"/></contactPerson> <streetAddress><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Street Address:')]/child::*[2])"/></streetAddress> <city><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'City:')]/child::*[2])"/></city> <provinceState><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Province/State:')]/child::*[2])"/></provinceState> <countryRegion><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Country/Region:')]/child::*[2])"/></countryRegion> <zip><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Zip:')]/child::*[2])"/></zip> <telephone><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Telephone:')]/child::*[2])"/></telephone> <mobilePhone><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Mobile Phone:')]/child::*[2])"/></mobilePhone> <fax><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Fax:')]/child::*[2])"/></fax> <website><xsl:value-of select="normalize-space(.//tr[starts-with(child::*[1],'Website:')]/child::*[2])"/></website> </pclass> </xsl:for-each> </xsl:if>
+/contactinfo.html$
1
http://shuangstar.en.alibaba.com/contactinfo.html http://susantrade.en.alibaba.com/contactinfo.html http://www.alibaba.com/member/priceshoesnorbert/contactinfo.html
任务示例二:抓取阿里巴巴中文搜索结果中相关企业的联系信息
test-alibaba-chinese
http://search.china.alibaba.com/search/company_search.htm?tracelog=po_searchcompany_select_bf&tracelog=&keywords=%BC%D2%BE%D3%D3%C3%C6%B7&submit=+%D6%D8%D0%C2%CB%D1%CB%F7+
-\.(gif|jpg|png|txt|css|js)$
5
0
3
否
localhost
6373
手动运行
<xsl:for-each select="//div[@class='offer']"> <pclass name="_SEED_"> <url><xsl:value-of select="resolve-uri(.//div[@class='info']/span/a/@href,$baseuri)"/></url> </pclass> </xsl:for-each>
+http://search.china.alibaba.com/company/%E5%AE%B6%E5%B1%85%E7%94%A8%E5%93%81/(\d{1,}).html
1
http://search.china.alibaba.com/company/%E5%AE%B6%E5%B1%85%E7%94%A8%E5%93%81/2.html http://search.china.alibaba.com/company/%E5%AE%B6%E5%B1%85%E7%94%A8%E5%93%81/8.html
<xsl:for-each select="//div[@class='contacts'][1]"> <pclass name="test.AlibabaContactInfoCn"> <genid><xsl:value-of select="$baseuri"/></genid> <contactPerson><xsl:value-of select=".//div[@class='mp_r']//a[1]"/></contactPerson> <telephone><xsl:value-of select="substring-after(./ul/li[starts-with(.,'电')],':')"/></telephone> <fax><xsl:value-of select="substring-after(./ul/li[starts-with(.,'传')],':')"/></fax> <streetAddress><xsl:value-of select="substring-after(./ul/li[starts-with(.,'地')],':')"/></streetAddress> <zip><xsl:value-of select="substring-after(./ul/li[starts-with(.,'邮')],':')"/></zip> <website><xsl:value-of select="substring-after(./ul/li[starts-with(.,'公')],':')"/></website> </pclass> </xsl:for-each>
+/contact/
<xsl:variable name="tmp">'</xsl:variable> <pclass name="_SEED_"> <url><xsl:value-of select="resolve-uri(substring-before(substring-after(//li[starts-with(@class,'headerMenuLi') and contains(.,'联系方式') and starts-with(@onclick,'window.location.href=') ]/@onclick,$tmp),$tmp),$baseuri)"/></url> </pclass>
1
http://chsp.cn.alibaba.com/athena/contact/chsp.html http://jinmaiqxh.cn.alibaba.com/athena/contact/jinmaiqxh.html http://cmgsguocj.cn.alibaba.com/athena/contact/cmgsguocj.html