
For the vertical search engine, web spider is more important than other tools, because data are all collected by the spider. There are many spider used in the vertical search engine. It is diffcult to manage these spiders if you have no more effective management strategy. In today's internet world, there are too many dynamic web page which partial datas generated by javascript. How to fetch those data is more and more important for the vertical search spider.
However, we can use Seaspider to do these things easily.
Seven Key Functions
1. Operates through browser
After Seaspider started, user can open browser, visit http://localhost:6070, start look up system information, manage task, and so on. All operations are done by browser, it's so convenient and easy.
2. How to persist data determined by user
Seaspider provides IDataPersist interface for persist crawling data. User can store data to file, database.
3. Use javascript as spider's language
Language employed by spider can be compiled language such as C/C++, can be dynamic language such as javascript, ruby,python. Dynamic language is more suitable for spider, because write easy, modify easy, and can run at once. Seaspider use javascript as it's spider language.
Seaspider provides a document object for spider task. By this object, spider task can extract any data in the document from any location by XPATH, and persit these data. The following code can save text content of a web page:
var map = new java.util.HashMap();
map.put('body',document.string('/html/body'));
document.saveData(map);
document.string : fetch text content of specific node, document.saveData : persist map data.
4. Various schedule time
Seaspider provides various schedule time for task: run manually, run every N minutes, run every N hours, run at HH:MM every day...
Every task has its schedule time. Seaspider can run the task at specific time after task starts.
5. Use Seaflower to crawl web page
Through Seaflower, Seaspider can get full data in web page including contents generated by javascript. Not only can It get normal link (<a href="URL">), but also execute javascript links, such as <a href="javascript:..." > and <a href="#" onclick="..."> .
6. Support various databases
Seaspider supports PostgreSQL ,MySQL,Oracle,SQL Server and embedded database HSQLDB. HSQLDB has already embedded in Seaspider, it's suitable for user testing and light crawl task. no need for install it.
7. Support Windows and Linux sytem
Seaspider, make vertical search more easier!
seaspider-4.4-installer.exe
(For Windows)
seaspider-4.4-fc9.tar.gz
(For Fedora Core 9 Linux)
seaspider-4.4-el5.tar.gz
(For RedHat EL 5/CentOS Linux)
*Seaspider Install*
WINDOWS: Double click Seaspider installer, at last, start Seaspider service.
LINUX: Unpack Seaspider package, execute "bin/seaspider start", start Seaspider service.
After Seaspider started, please open your browser, visit the port Seaspider used, for example, http://localhost:6070, continue installing - select language, administrator name and password, database settings ...
 |
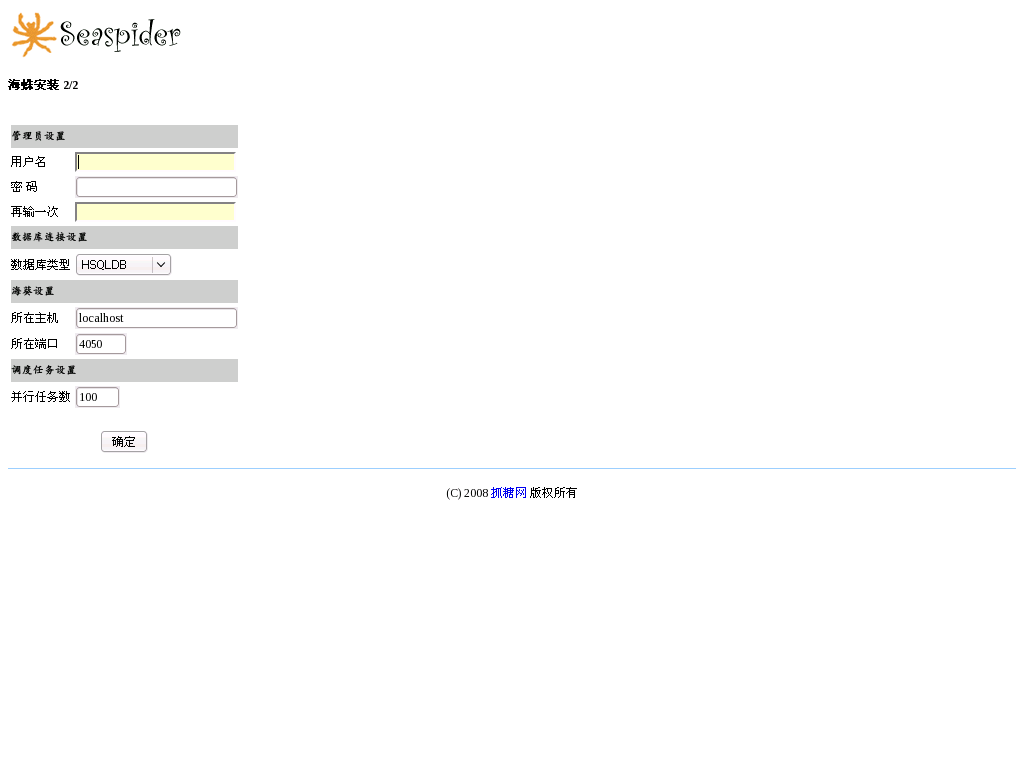 |
|
| Install Step 1 | Install Step 2 |
Seaspider Login
After completed install process, please open your browser, visit the port Seaspider used, for example, http://localhost:6070, input administrator name and password, click "OK", login Seaspider.
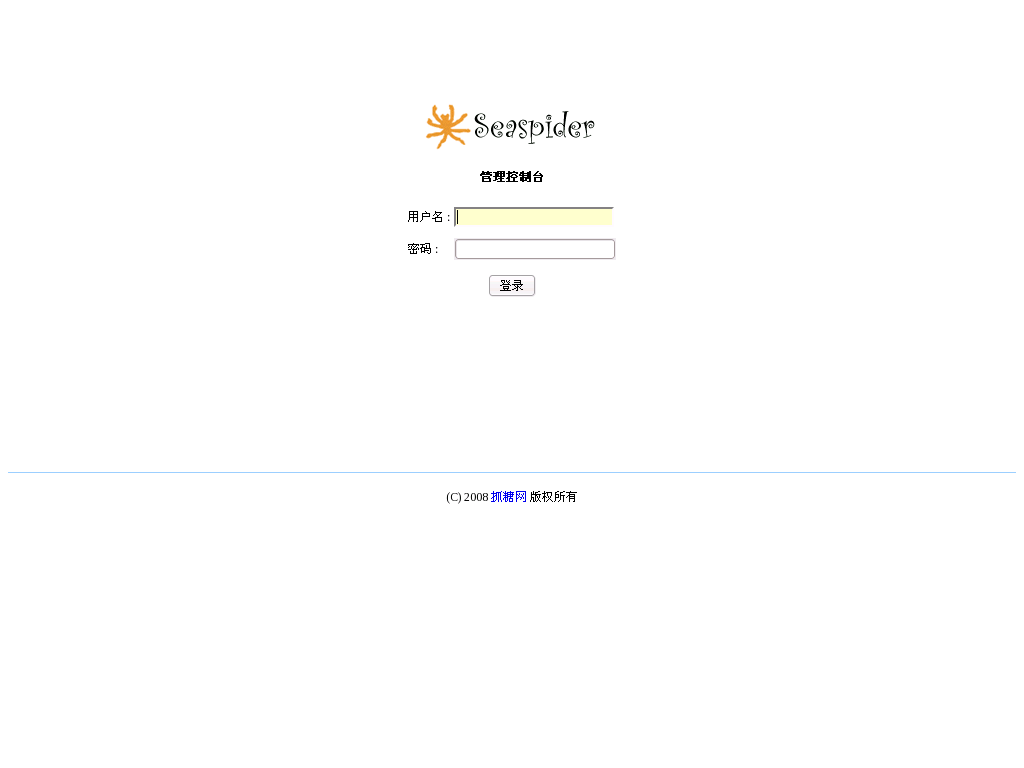 |
| Seaspider Login |
*Seaspider Console
In Seaspider console, you can look up system information, manage task, change login name and password.
1.System Information
System information shows Seaspider's version and register status. If Seaspider is not registered, user must provide MAC address which displayed in System information. After you got register code, click "register now" to register Seaspider.
 |
| Seaspider Console - System Information |
2.Task Management
In Seaspider, every data extraction work should be defined as a task, every task runs in multi-threaded way, maximum thread defined in task configuration. Each task thread just like conventional web spider or crawler.
 |
| Seaspider Console - Task Management |
1) New task
Click "New" to create new task, input task name, seed URLs, max depth,max thread,url filter, wait time, persist class, data process script and schedule time.
Url filters are written by regular expression, each filter must starts with + or -, + stands for allow, - stands for disallow. Data persist class must implement IDataPersist interface, pack them as jar file, store to userprovided directory in Seaspider home directory. Seaspider provides a data persist class - DataDump for debug use. Data process script is written by javascript, use XPATH/DOM extracting data.
 |
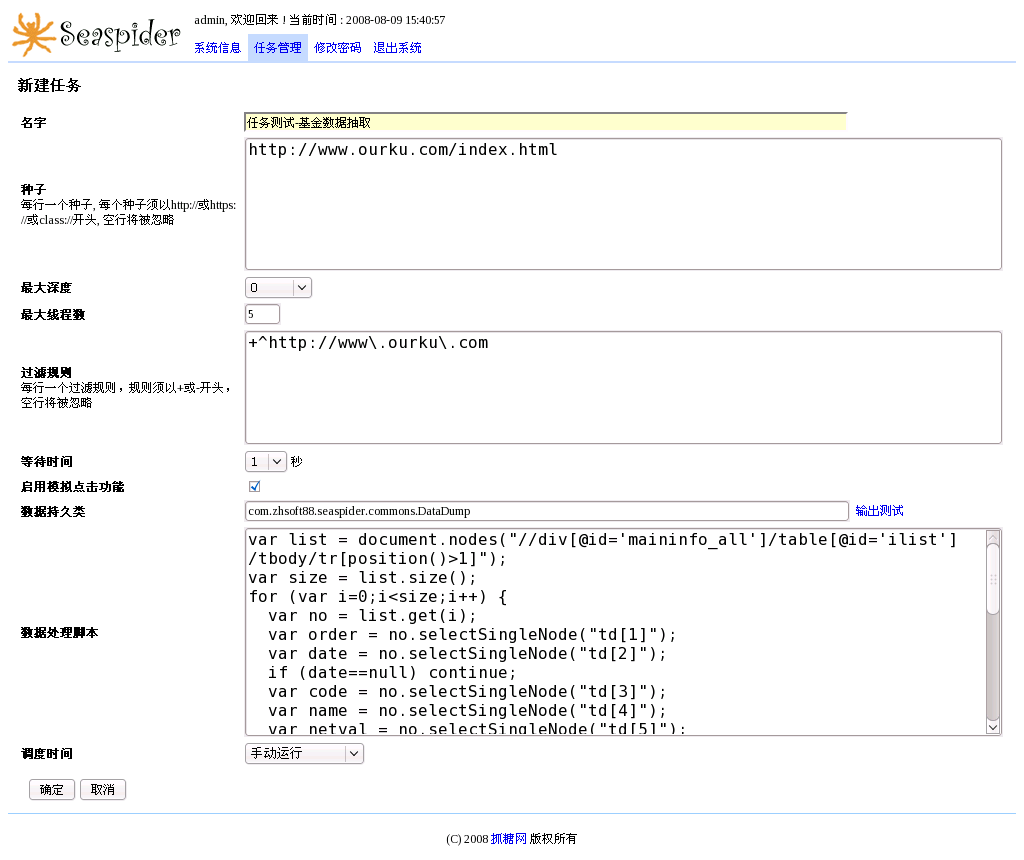 |
|
| Seaspider Console - Edit task 1 | Seaspider Console - Edit task 2 |
2) Edit task
Click "Edit" to modify task definition.
3) Delete task
4) Copy task
Create new task by copying a similar task.
5) Start task
Click "Start" to start task which will execute at specific time.
6) Stop task
Click "Stop" to stop the running task.
Run manually task right now.
3. Change password
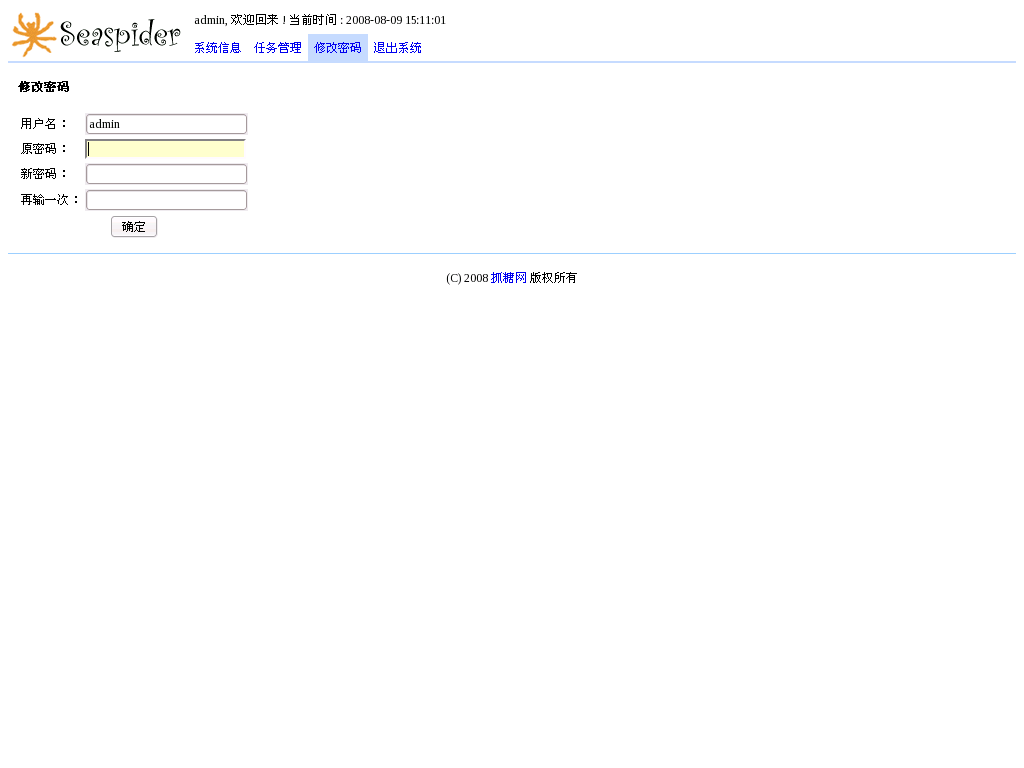 |
| Seaspider Console - Change password |
*programming interface
Seaspider has a inner object - document, which stands for the current document. It has some properties:
(1) url Current URL (2) opnode XPATH of current node
It has some methods:
A. String text(String xpath) get text content of node by specific xpath B. String string(String xpath) get string value of node by specific xpath C. Node node(String xpath) get node of specific xpath D. List<Node> nodes(String xpath) get node array of specific xpath E. void saveData(Map data) save map data through user provided persist class
Method A-E: for analysis document content. Method E: save map data. Node is Node class of dom4j.
var ns = document.nodes('//div[@id='text_sider']//div[1]/ol/li[@class='li_info']/span/a');
var text = '';
var size = ns.size();
for (var i=0;i<size;i++) {
text += ns.get(i).getText());
}
* Seaspider spider script development * Require: 1. Install JDK and eclipse 2. add dom4j and seaspider-*-commons.jar to your build path Development: 1. Use Seaflower, get xml source of specific web page. 2. Write java codes to analysis and save web data, ensure it correct. 3. Transform java source codes to javascript: Change "int a;" to "var a;", "Map map = new java.util.HashMap();" t "var map = new java.util.HashMap();", etc. 4. Create new task, fill javascript to data process script, start task and test.
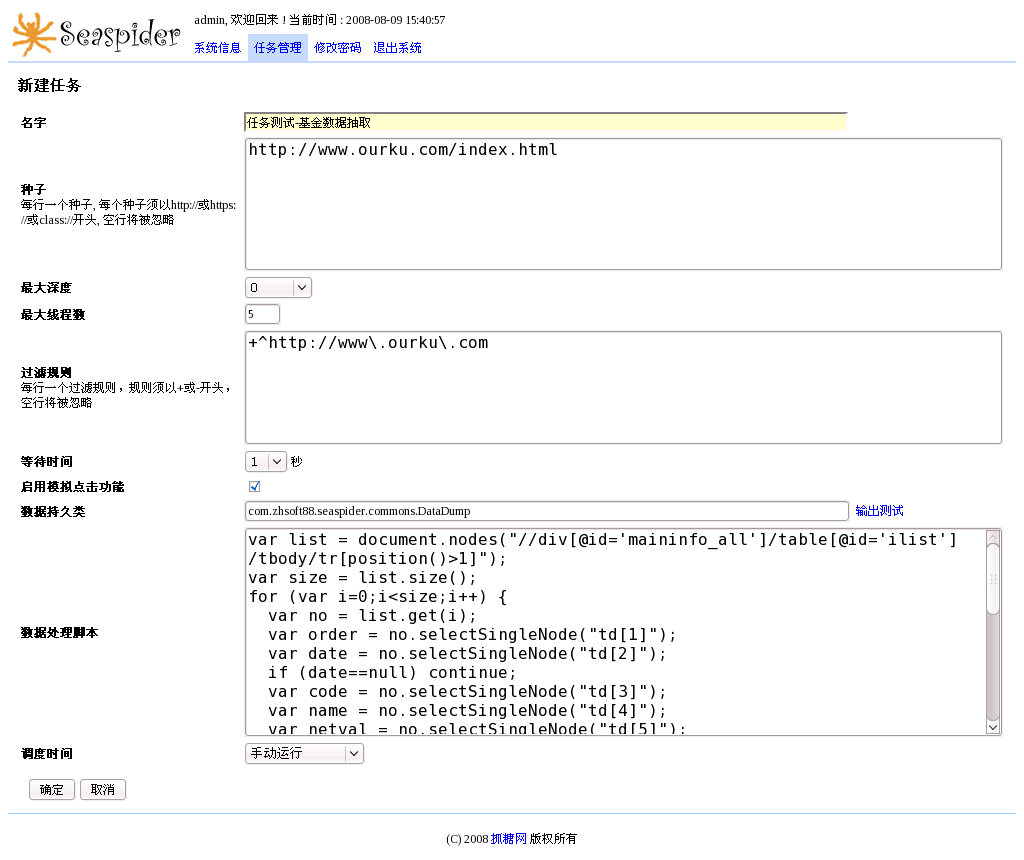 |
| Seaspider Console - ourku |
Seed: http://www.ourku.com/index.html
Max depth: 0
URL filter: +^http://www\.ourku\.com
Data persist class: com.zhsoft88.seaspider.commons.DataDump
Data process script:
var list = document.nodes("//div[@id='maininfo_all']/table[@id='ilist']/tbody/tr[position()>1]");
var size = list.size();
for (var i=0;i<size;i++) {
var no = list.get(i);
var order = no.selectSingleNode("td[1]");
var date = no.selectSingleNode("td[2]");
if (date==null) continue;
var code = no.selectSingleNode("td[3]");
var name = no.selectSingleNode("td[4]");
var netval = no.selectSingleNode("td[5]");
var totalval = no.selectSingleNode("td[6]");
var growval = no.selectSingleNode("td[7]");
var growrate = no.selectSingleNode("td[8]");
var map = new java.util.TreeMap();
map.put('order',order.getStringValue());
map.put('date',date.getStringValue());
map.put('code',code.getStringValue());
map.put('name',name.getStringValue());
map.put('netval',netval.getStringValue());
map.put('totalval',totalval.getStringValue());
map.put('growval',growval.getStringValue());
map.put('growrate',growrate.getStringValue());
document.saveData(map);
}